이전 포스팅에서 언급한 선형 시스템에서 우리가 하려고 하는 일은 측정 가능한 y의 값으로 부터 시스템의 상태인 x를 예측해 내는 것
입니다.
이미 시스템이 어떻게 동작하는지 표현 하는 공식의 모델링도 했고, 위치를 측정할 수도 있습니다. 그럼 어떻게 상태 x를 예측할
수 있을 까요? (아니면 예측된 값이 최적의 결과라고 확신 할 수 있을까요?)
일단 시스템 동작의 결과(원하는 상태 x) 모두를 정확하고도 직접적으로 측정할 수는 없더라도 시스템 상태를 그야말로 정확하게 예측
할 수 있는 예측 시스템 (estimator)이 있으면 얼마나 좋을까요? 그 시스템을 고르는 결정 방법은 또 뭘까요?
일단 다음의 두가지 (수학적인) 요구 조건이 있다고 합니다. (저자는 머리속에 떠오른다는데 왜? 난 아무 생각이 없이 머리속이 백짓장 마냥 변하는 걸까요? ㅎㅎㅎ)
우선 첫번째로, 우리가 예측한 상태의 평균값이 실제 시스템의 (그야말로 - 100% exact truth) 진짜 상태의 평균과 동일하다면 좋다고 합니다. 이 의미는 통계적인 평균값이 다를 경우 (즉, Kalman Filter는 통계적인 기반을 가지고 있다는 뜻 입니다) 예측이 어느 특정 방향으로 바이어스 (bias)가 발생하게 된다는 뜻 입니다. 다시, 수학적으로 (정확히는 통계학적으로) 추정 (또는 예측치)의 기대값(expected value)이 실제 시스템의 기대값과 같아야만 한다는 것 입니다.
두번째로, 현재 예측된 시스템의 상태와 실제 상태의 차이가 작으면 작을 수록 좋다고 합니다. 역시, 수학적으로 가능하면 가장 작은 오류 변형이 발생하는 Estimator를 찾아야 합니다.
물론 이런 얘기를 하는 이유가 이미 수많은 과학자들과 수학자들이 알아보기로 KF가 위의 특성을 다 따르기 때문인 것은 당연하겠지요. 하지만 여기서 KF 를 이용한다고 해서 모든 부분에 최상의 결과를 기대할 수 있는 것은 아니며 이를 위해서 시스템에 영향을 미치는 잡음이 어느 정도의 가정에 맞아 들어 가야만 합니다.
이전에 언급된 프로세스 잡음 (Process Noise) w와 측정 잡음 (Measurement Noise) z의 경우 우리는 이들 잡음의 평균이 0 이라고 (즉, White Noise 를 말합니다) 가정 하고 있습니다. 또한, w와 z 간에는 상호 작용(correlation)이 없어야 합니다. 즉, 어떤 시간 k에서든 w_{k}와 z_{k}는 독립적인 랜덤 변수(independent random variable) 이어야 한다는 것 입니다.
이제, 노이즈 코베리언스 메트릭스 (Noise Covariance Matrix)인 S_{w}와 S_{z} (Process 및 Measurement 노이즈 각각)는 다음과 같이 정의 됩니다.
Process noise covariance :
Measurement noise covariance :
여기서 w^{T} 와 z^{T}는 w와 z 노이즈 벡터의 트랜스포즈 (전치 - Transponse)를, E(...) 는 기대값을 의미 합니다. 이들이 어떻게 나타나는지 실예는 좀 있다가 설명하겠습니다.
일단 이리하여 Kalman Filter를 소개하기 위한 준비 과정을 거의 마무리 했습니다.
그럼 KF는 무엇 일까요? KF를 표현하는 여러가지 공식이 있지만 가장 일반적인 공식을 (사실 원문의 공식 입니다) 보면 다음과 같습니다.

위의 수식을 보는 순간 머리가 상당히 아플 수는 있겠습니다만 (저는 다시 머리속이 하얗게 변하드라는 ㅎ) 잠시만 참고, 위 3개의 공식을 찬찬히 봐 주시기 바랍니다. 우선 -1이 의미하는 것은 메트릭스 인버젼 (maxtrix inversion) 이며 T는 이전에 설명 드린 트랜스포(transposition) 입니다.
K 는 칼만 게인(Kalman Gain)을, P는 예측 오류 코베리언스 메트릭스(the estimation error corvariance matrix) 라고 합니다.
중간에 꺽어진 모자를 쓰고 있는 어디서 본 듯한 x는 상태 예측 공식 입니다. 이 공식에 우선 집중을 해 보면
앞의
그래서 두번째 항인 아래 수식을(correction term을 어거지로 번역하면) 보정항 이라고 하며 새로 수집된 계측 자료에 의해서 얼마나 많은 보정을 예의 시스템 상태 예측에 가해야 하는지를 나타냅니다. 아래의 공식에서도 유의 하실 것은 계측 자료에서 이전의 출력 수식(measurement 역시 예측 한다는 뜻 입니다)을 뺀 값(많은 KF 관련 문서에서 이 식을 이노베이션 - Innovation - 이라고 합니다)을 칼만게인과 곱하는 부분 입니다.
Correction Term:
KF 공식에서 칼만게인 부분 만을 좀 더 주의 깊게 살펴 보면, 만일 센서의 노이즈가 큰 경우 결국 S_{z} (Measurement noise covariance)가 커지게 되고, K의 값이 작아지게 됩니다. 결과적으로 다음에 이어질 상태 예측 공식에서 새로 수집된 자료 내용에 대한 신뢰가 떨어지게 되며 시스템 상태 예측에 무게가 실리게 됩니다.
반대로, 노이즈가 작은경우, S_{z}가 작아지고, K는 커지며 다음 상태 예측 공식에서 더 많은 신뢰를 (즉, 실측 자료의 내용이 좀더 많이 반영 되는) 가져오게 됩니다.
마지막의 Error Covariance Matrix 의 경우는 프로세스 노이즈와 계측 노이즈, 이전에 (즉, k번째에) 계산된 Error Covariance Matrix 를 이용해서 업데이트 됩니다.
원문에서 별다른 스포트 라이트를 받고 있지는 못 합니다만 실제 이 메트릭스는 시스템의 상태 및 측정 오류등의 변화량등의 값들을 추적/기억하고 있습니다. 로보틱스(특히 SLAM)에서는 이 메트릭스와 상태 벡터를 새로 확인되어진 랜드마크(센서에 의해서 지표로 인지 가능한 마크)를 추가해서 전반적인 상태 변화를 추적하는데 사용되기도 됩니다.
예제
이제 이전에 다루던 자동차 관련 예측을 계속 진행해 보겠습니다.
원문 저자가 미쿡분이다 보니 피트를 단위로 사용하셔서 좀 현실적이지 않은 부분이 있습니다만 예제에서 주요 파라미터로 다음과 같은 값을 지정하고 있습니다 :
1. 입력 가속 : 1 foot / s^2
2. 가속 노이즈 : 0.2 feet / s^2
3. 위치 결정 노이즈 : 10 feet
4. 측정은 1초당 10회 (즉, 10Hz, T=0.1)
위의 오류들은 모두 1-sigma (one standard deviation) 내의 값들 입니다.
아래의 수식에서 바뀐 부분은 T와 관련된 부분이 실제 값으로 바뀐 것 뿐 입니다. 참고하고 있는 원문에서는 T (시간 변화율)를 0.1초로 보고 있습니다.

출력 노이즈인 S_{z}의 경우 단순 스칼라 값이며 위의 파라미터를 보면 10 feet이므로 결국 100 (= 10*10 ) 이 됩니다.
S_{w}를 구하는 과정을 보죠. 상태는 위치와 속도의 2개 정보를 가지고 있습니다.
위치는 가속도에 대해서 0.005 배에 비례하고 가속 노이즈가 0.2 feet/s^2이기 때문에 위치노이즈의 편차 (variance)는 (0.005 ^2 ) * 0.2 ^ 2) = 10^-6 (10의 -6승)이 됩니다.
유사하게, 속도의 경우 가속에 대해서 0.1배 만큼 비례하며 결국 (0.1 ^2 ) * 0.2 ^ 2) = 4 *10^-4 이 됩니다.
결국, 메트릭스는 아래와 같이 표현 됩니다. 여기서 vp = pv = (0.005 * 0.2) * (0.1 * 02) = 2 *10^-5 입니다.

여기까지 수집된 결과들과 수식들을 아래의 문서에 도식화 하고 있는 것과 같은 무한룹에 빠지도록 프로그램을 작성하면 되겠습니다.

http://www.cs.unc.edu/~tracker/media/pdf/SIGGRAPH2001_CoursePack_08.pdf
'Mathematical Theory' 카테고리의 다른 글
| Linear Systems(선형시스템) (0) | 2009.11.18 |
|---|---|
| Linear system (0) | 2009.11.18 |








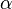






![y[n] = \sum_{k=-\infty}^{\infty} { h[n,k] x[k] }](http://upload.wikimedia.org/math/0/6/8/0687338756ed6fb7869b659f41ab05f7.png)
![y[n] = \sum_{m=-\infty}^{\infty} { h[n,n-m] x[n-m] }](http://upload.wikimedia.org/math/3/b/1/3b1a10182956883fd5876b69db5e1ee7.png)









.jpg)